Things I Love About Stata -- egen mean
30 May 2011egen mean
I work a lot with clustered data, including group psychotherapy data (people clustered in groups), individual psychotherapy data (people clustered within therapists), and longitudinal data (observations clustered within people). Consequently, I often need to create cluster-level means and grand means for graphing and modeling. The egen mean function makes creating means easy. Combining egen mean with by processing in Stata makes this a breeze, even when cluster sizes differ.
egen mean for grand means
The egen function is used to create new variables. To create a mean with egen we use the following syntax:
egen nameofnewvariable=mean(nameofoldvariable)
We can download the the pig data from the xtmixed help.
webuse pig, clear
The variables are id, week, and weight.
list in 1/15, clean
id week weight
1. 1 1 24
2. 1 2 32
3. 1 3 39
4. 1 4 42.5
5. 1 5 48
6. 1 6 54.5
7. 1 7 61
8. 1 8 65
9. 1 9 72
10. 2 1 22.5
11. 2 2 30.5
12. 2 3 40.5
13. 2 4 45
14. 2 5 51
15. 2 6 58.5
We can create a grand mean (say, for creating centered variables) of weight using egen.
egen grandweight=mean(weight)
This creates a new variable that is equal to the grand mean for weight (it is a constant across all variables)
list in 1/15, clean
id week weight grandw~t
1. 1 1 24 50.40509
2. 1 2 32 50.40509
3. 1 3 39 50.40509
4. 1 4 42.5 50.40509
5. 1 5 48 50.40509
6. 1 6 54.5 50.40509
7. 1 7 61 50.40509
8. 1 8 65 50.40509
9. 1 9 72 50.40509
10. 2 1 22.5 50.40509
11. 2 2 30.5 50.40509
12. 2 3 40.5 50.40509
13. 2 4 45 50.40509
14. 2 5 51 50.40509
15. 2 6 58.5 50.40509
##egen mean for cluster means##
We can combine egen mean with by to compute cluster means. (Remember that id is the cluster id variable.)
by id: egen groupweight=mean(weight)
If the id variable isn’t sorted, then you can change the code to:
by id, sort: egen groupweight=mean(weight)
This creates a variable that is equal to the cluster mean for each cluster. That is, its value is constant within clusters but varies across clusters.
list in 1/15, clean
id week weight grandw~t groupw~t
1. 1 1 24 50.40509 48.66667
2. 1 2 32 50.40509 48.66667
3. 1 3 39 50.40509 48.66667
4. 1 4 42.5 50.40509 48.66667
5. 1 5 48 50.40509 48.66667
6. 1 6 54.5 50.40509 48.66667
7. 1 7 61 50.40509 48.66667
8. 1 8 65 50.40509 48.66667
9. 1 9 72 50.40509 48.66667
10. 2 1 22.5 50.40509 51.33333
11. 2 2 30.5 50.40509 51.33333
12. 2 3 40.5 50.40509 51.33333
13. 2 4 45 50.40509 51.33333
14. 2 5 51 50.40509 51.33333
15. 2 6 58.5 50.40509 51.33333
##Looking at missing data##
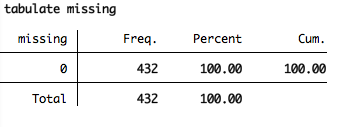
You can also use egen to generate a variable to examine missing data on each row. This can be particularly important when you are generating scale variables, or variables that will be combining values of multiple variables. For example, in the pig data above, if they were to weigh the pigs a second time (weight2) and create a variable of the difference between Time 1 and 2, if any pig were missing one of the time points, the difference score would not be accurate. In this hypothetical example, you could use egen combined with rowmiss to create a missing variable to examine this:
egen missing = rowmiss(weight weight2)
Then you can use the tabulate command to identify if any values are missing:
tabulate missing
Take a look at the other functions of egen–they’re remarkably useful.