Stata: Dummy Coding
05 Oct 2011Introduction
This post will illustrate how to:
- Use the generate and replace commands to create dummy variables.
- A second use of the generate command to dummy variables that is simpler that #1.
- Using tabluate to create dummy variables.
Dummy coding is used when you have nominal categories, meaning the groups are assigned a value for coding purposes, but the values don’t represent more or less of anything. For example, I might code three different categories of race and coded them as follows: Caucasian = 1, African American = 2, Hispanic = 3. The numbers are for coding purposes only, 3 is not actually any bigger or more than 1. But if we use these in a regression (or any other) analysis, the numbers will be treated as continuous - not categorical. So we need to create dummy variables. Generally, we create k-1 new groups, where k is the total number of groups, and one group is used as the reference sample, or the group we want to compare other groups to.
Method 1: Using generate and replace
We’ll use the built in system data systolic.
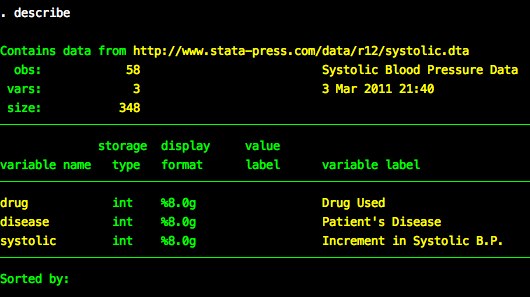
The drug variable has 4 levels.
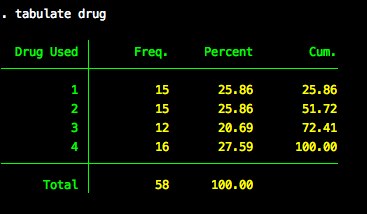
Consequently, we’ll need to make 3 dummy coded indicator variables to represent drug. We’ll use level 4 as the reference category. We’ll use a series of generate and replace commands to create the variables. This is definitely the brute-force way to make the variables, but it makes the logic behind creating dummy variables clear.
generate drug1=1 if drug==1
replace drug1=0 if drug!=1
generate drug2=1 if drug==2
replace drug2=0 if drug!=2
generate drug3=1 if drug==3
replace drug3=0 if drug!=3
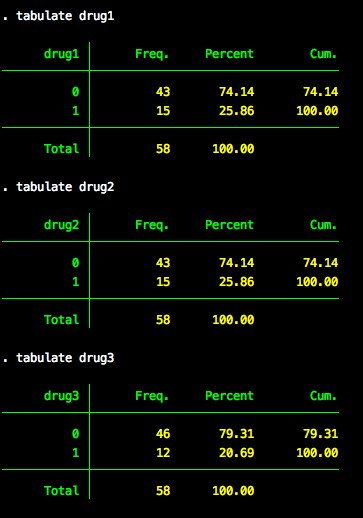
Tabulating each of the dummy variables – drug1 - drug3 – we see they match our original tabulation.
Method 2: Use generate only
We can also use a feature of the generate command to create a new variable that takes on the values 1 and 0. So, for example, if we want to create drug1, where drug1 is equal to 1 when the drug condition equals 1, we say:
generate drug1=drug==1
This creates a variable that is 1 when drug equals 1 (recall that == is a logical evaluator) and 0 any other time. If we want to use the fourth condition as the reference category, we repeat the generate command for drug2 and drug3.
generate drug2=drug==2
generate drug3=drug==3
Method 3: Use the generate option of tabulate
The function tabulate has an option called generate. The generate option takes one argument called stubname, where stubname is the stub of the new variable names created by the option. In our examples so far, the stub has been drug. Unlike the examples we have done so far, this method will create as many dummy variables as there are levels of the categorical variable (4 in our case). In our example, we type:
tabulate drug, generate(drug)
We now have four new variables in our dataset – drug1-drug4.